Intro
-
최근 BERT 및 XLNet 등 자연어 처리를 딥러닝으로 처리하려는 모습들이 보였다.
-
직접 구현하지 않더라도 아이디어를 얻는 차원에서 어떻게 구현됐는지 알고싶어서 이것저것 보던중 Transformer라는 걸 알아야한다는 걸 알게 됐다.
-
그런데 Transformer를 보려고하니 알아야하는 것들이 생각보다 많아서 하나씩 살펴보려고 하는데 그중 하나가 바로 Attention이라는 것이다.
-
여기서는 딥러닝에서 Attention이란 무엇인지 살펴보려한다.
Attention은 왜 나오게 됐을까?
-
기존 seq2seq 모델을 만들때 RNN이 주로 사용되었다.
-
여기서 말하는 seq2seq는 Encoder를 통해 Input Vector를 받아서 Decoder를 통해 Output Vector를 출력하는 모델을 말한다.
- 하지만 RNN의 경우 한계점이 존재했다.
- 1) Vanishing gradient 문제
- 2) Encoding하는 과정에서 고정된 크기의 벡터로 압축시킬때 발생하는 정보 손실문제
- 특히, 번역 문제에서 길이가 긴 문장을 번역할 경우 성능이 떨어지는 현상으로 이어진다.
- 그래서 이러한 문제를 해결하고자 Attention 기법이 등장했다.
Attention의 아이디어
-
기본적인 아이디어는 “다음 시퀀스를 예측할 때 Input의 어느 정보에 집중하여 더 정확하게 예측할 것인지”이다.
- 즉, 아래와 같은 문장이 2개 있다고 해보자.
- 1) I saw my friend that took a bus.
- 2) 나는 버스를 탄 내 친구를 봤었다.
- 영어 -> 한글 번역문제라고 했을 때 “친구”라는 단어는 영어문장의 어느 부분에 집중을 해야하는 것일까?
- “bus” 보단 “friend”에 더 집중을 해야하지 않을까?
Seq2seq with Attention
- Attention은 처음에 나올 당시 단독적으로 쓰이기 보단 Seq2seq 모델에 같이 사용되었다.
- 그래서 본 문서에서는 Seq2seq에서 어떻게 Attention이 사용됐는지 같이 살펴본다.
- 논의를 위해서 Seq2seq모델은 LSTM셀이라 가정하고, 여러가지 Attention 중 Dot-Product Attention 을 중심으로 설명한다.
- 우선 Attention은 아래와 같은 구조를 지닌다.

- Attention의 구조를 이해하기 위해서는 아래 3가지를 알아야한다.
- 1) query
- 2) key
- 3) value
-
사실 특별한 것이라기보단 Attention 구조를 이루는 구성요소정도로 생각하면 된다.
- Seq2seq with Attention으로 보면 3가지 구성요소는 아래와 같은 의미를 뜻한다.
- 1) query : Attention layer의 input으로 t-1 시점의 decoder셀의 hidden state
- 2) key & value : 모든 시점의 encoder 셀의 hidden state
- Attention에서 반환하는 output은 다음과 같은 순서에 의해 계산된다.
- 1) 입력받은 Query에 대해서 모든 key와의 유사도를 각각 구한다.
- 2) 이 유사도를 기반으로 Softmax함수를 이용하여 각 key에 대응하는 가중치를 구한다.
- 3) 각 key에 대응하는 value와 가중치를 이용하여 weighted sum을 구한다.
- 간단하게 Attention이 output을 반환하는 순서를 봤으니 이번에는 그림을 통해 살펴보도록하자.
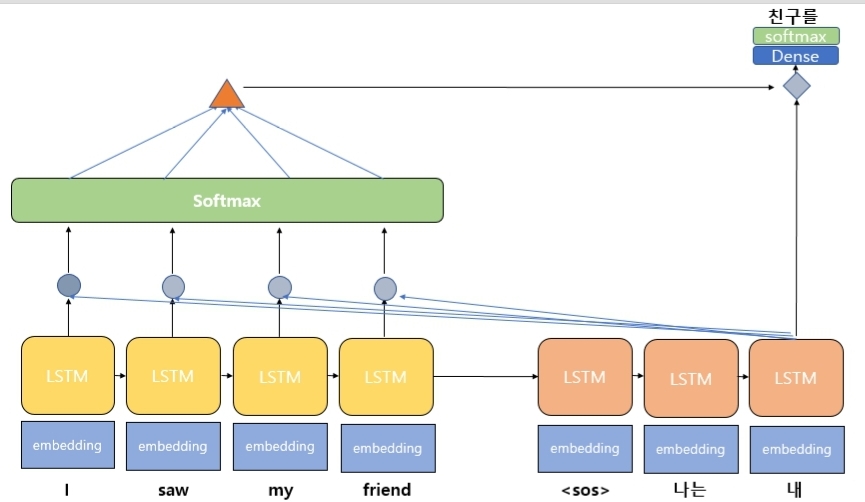
-
위 그림은 decoder의 세번째 LSTM 셀에서 단어를 예측할 때, Attention을 사용하는 모습을 보여준다.
-
Attention을 사용한다는 의미는 해당 셀에서 예측을 수행시 encoder의 모든 input 단어들의 정보를 다시 한번 참고한다는 의미이다.
-
input 단어에 해당하는 I, saw, my, friend는 encoder의 각 시점의 embedding layer를 타고 들어가서 각 단어는 word vector로 변환된다.
-
변환된 vector는 LSTM 셀의 input으로 사용되어 계산된 결과로 encoder의 각 시점별 hidden state를 가지게 된다.
-
이 hidden state와 이전 시점의 decoder hidden state를 이용하여 유사도를 측정한다.
-
측정된 유사도를 기반으로 각 단어에 대응하는 가중치를 구한다.
-
각 단어별 벡터와 가중치를 이용하여 weighted sum을 구하면 Attention의 output이 나온다.
-
이를 context vector라고도 하는데 해당 벡터는 이전 시점의 decoder hidden state와 결합(concatenate)한다.
-
결합된 벡터를 기반으로 이후에는 기존 RNN의 메커니즘과 동일하게 작동된다.
정리
- 지금까지 Attention에 대해서 아주 간략하고 압축적으로 설명해봤다.
- 처음에는 Seq2seq 모델의 성능을 보정하는 용도로 Attention이 소개되었지만, 요즘은 Attention 자체만으로 만든 모델이 Seq2seq의 성능을 뛰어넘기도 한다.
- 해당 글로 이해가 안될 수 있으니 아래 참고사이트를 한번 살펴보기 바란다.
- https://wikidocs.net/22893
- https://www.d2l.ai/chapter_attention-mechanism/attention.html
- https://www.d2l.ai/chapter_attention-mechanism/seq2seq-attention.html